Imposter Syndrome in Data Science
Lately I’ve been hearing and reading lots about imposter syndrome, and I wanted to share a few thoughts on why imposter syndrome is so prevalent in data science, how I deal with it personally, and ways we can encourage people who are feeling the impact.
Why is imposter syndrome so prevalent in data science?
Data science has a few characteristics which make it a fertile ground for imposter syndrome:
Data science is a new field.DJ Patil and Jeff Hammerbacher were the first titled “data scientists” only about 7(!) years ago (around 2011). Since then, as we’ve all been figuring out what data science *is*, differing definitions of “data scientist” have led to some confusion around what a data scientist should be (or know). Also, because “data science” wasn’t taught in colleges (as such) before then, the vast majority of data scientists do not have a diploma that says “data science”. So, most data scientists come from other fields.
Data science is a combination of other fields.Depending on who you ask, a data scientist is some combination of an analyst / statistician / engineer / machine learning pro / visualizer / database specialist / business expert. Each of these are deep positions in their own right, and it’s perfectly reasonable to expect that a person who comes to data science from any one of these fields will have significant gaps when it comes to the other fields on the list.
Data science is constantly expanding with new technologies.As computer memory becomes cheaper, open-source becomes more popular, and more people become interested in learning and contributing to data science and data-science-adjacent fields, the technology surrounding data science grows at a very healthy rate. This is fantastic for the community and for efficiency, but leads to lots of new technologies for data scientists to learn and a culture where there is pressure to stay “on top” of the field.
So, we have people from a variety of backgrounds coming to a new field with many applications whose boundaries aren’t clearly defined (thus causing inevitable gaps in their knowledge of that field as a whole), and where technology is changing faster than a single person can keep up with. That is the plight of a data scientist in 2018, and why so many people feel the effects of imposter syndrome.
My Secret for Dealing with Imposter Syndrome
Every single data scientist that I know (and you know) is learning on the job. It might be small stuff (like cool tools or keyboard shortcuts) or bigger stuff (like new algorithms or programming languages), but we’re all learning as we go, and I think it’s crucial that we acknowledge that. For me, it’s simultaneously really exciting to be in a field where everyone is learning, and also kind of intimidating (because what if the stuff I’m learning is stuff that everyone else already knows?), and that intimidation is a form of imposter syndrome.
The way that I’ve dealt with imposter syndrome is this: I’ve accepted that I will never be able to learn everything there is to know in data science -- I will never know every algorithm, every technology, every cool package, or even every language -- and that’s okay. The great thing about being in such a diverse field is that nobody will know all of these things (and that’s okay too!).
I also know that I know things that others don’t. I’ve built predictive models for dozens of colleges and non-profits, have experience on what it takes to create and analyze successful (and unsuccessful!) A/B tests, and am currently learning how to do machine learning models in production. These are not skills that everyone has -- there are people who know more about computer science than I do, or machine learning, or Macbook shortcuts -- and that’s okay. Diversity is a good thing, and I can learn from those people. There’s a great Venn diagram which illustrates the relationship between what you know and what other people know, and how they overlap. What you know is rarely a subset of what other people know; your knowledge overlaps with others and also sets you apart from others.
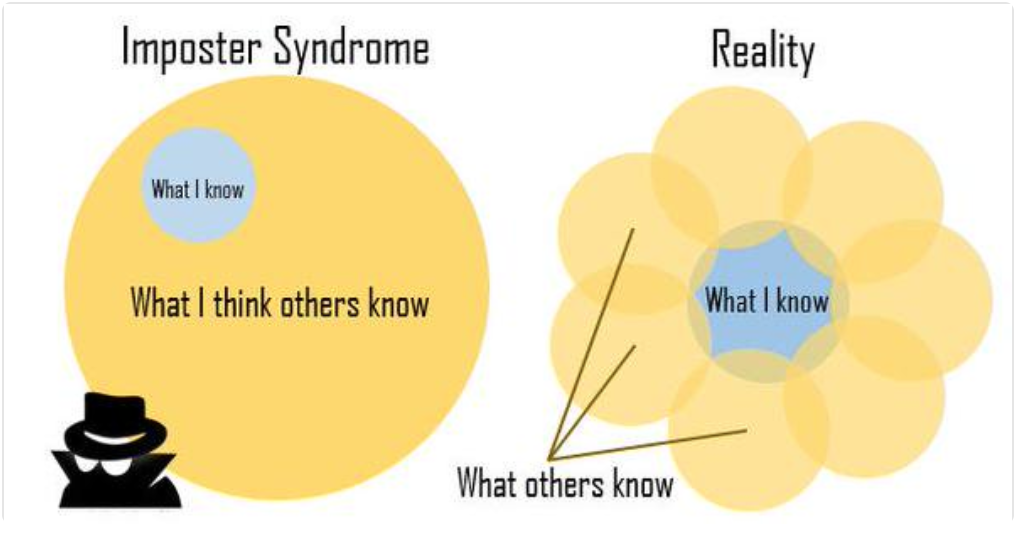
Community-wide Techniques for Reducing Imposter Syndrome
If we can agree that all data scientists are learning on the job, I think the best things that we can do for reducing imposter syndrome in the larger data science community are to be open in acknowledging it and to work towards fostering a healthy learning environment.
Get comfortable with “I don’t know”
I love when people say “I don’t know”. It takes courage to admit when you don't know something (especially in public) and I have a great deal of respect for people who do this. One way that we can make people more comfortable with not knowing things is to adopt good social rules (like no feigning surprise when someone doesn’t know a thing, and embrace them as one of today’s lucky 10,000 instead).
Don’t “fake it ‘til you make it”
Sure, it’s good to be confident, but the actual definition of an imposter is someone who deceives, and I think we can do better than “faking it” on our way to becoming better data scientists. “Faking it” is stressful, and if you get caught in a lie, can potentially cause long-term damage and loss of trust.
Encourage questions
The benefit to asking questions is two-fold:
1) You gain knowledge through conversation around questions
2) Asking questions publicly encourages others to ask questions too.Asking questions is exactly the kind of thing data scientist should be doing, and we should work to encourage it.
Share what you’re learningWhen I see others share what they’re learning about, it helps me put my own learning in perspective -- and whether I know much about the topic or not, it’s encouraging to see other people (especially more experienced people) talk about things that are new to them.I’ve started a personal initiative to track the things I’m learning each week on Twitter using the hashtag #DSlearnings. Feel free to have a look at the archives (I’d love to chat if you’re learning similar things!), and to add your own learnings to the hashtag.
A little bit of transparency goes a long way towards staving off imposter syndrome. We can embrace both being knowledgeable and not knowing things -- and do so in public.
**
I’d love to hear ways that others deal with imposter syndrome, and about things you’re learning (feel free to use #DSlearnings or make your own hashtag!) along the way.
PS: Thank you to @jennybryan and @dataandme for the Venn diagram!